Research
At the moment, my research interests broadly lie in the fields of robot learning and deep reinforcement learning. *Equal Contribution
2025
- CoRL
 DiWA: Diffusion Policy Adaptation with World ModelsAkshay L Chandra, Iman Nematollahi, Chenguang Huang, and 3 more authorsConference on Robot Learning (CoRL), 2025
DiWA: Diffusion Policy Adaptation with World ModelsAkshay L Chandra, Iman Nematollahi, Chenguang Huang, and 3 more authorsConference on Robot Learning (CoRL), 2025Fine-tuning diffusion policies with reinforcement learning (RL) presents significant challenges. The long denoising sequence for each action prediction impedes effective reward propagation. Moreover, standard RL methods require millions of real-world interactions, posing a major bottleneck for practical fine-tuning. Although prior work frames the denoising process in diffusion policies as a Markov Decision Process to enable RL-based updates, its strong dependence on environment interaction remains highly inefficient. To bridge this gap, we introduce DiWA, a novel framework that leverages a world model for fine-tuning diffusion-based robotic skills entirely offline with reinforcement learning. Unlike model-free approaches that require millions of environment interactions to fine-tune a repertoire of robot skills, DiWA achieves effective adaptation using a world model trained once on a few hundred thousand offline play interactions. This results in dramatically improved sample efficiency, making the approach significantly more practical and safer for real-world robot learning. On the challenging CALVIN benchmark, DiWA improves performance across eight tasks using only offline adaptation, while requiring orders of magnitude fewer physical interactions than model-free baselines. To our knowledge, this is the first demonstration of fine-tuning diffusion policies for real-world robotic skills using an offline world model.
- ICRA
 LUMOS: Language-Conditioned Imitation Learning with World ModelsIman Nematollahi, Branton DeMoss, Akshay L Chandra, and 3 more authorsIEEE International Conference on Robotics and Automation, 2025
LUMOS: Language-Conditioned Imitation Learning with World ModelsIman Nematollahi, Branton DeMoss, Akshay L Chandra, and 3 more authorsIEEE International Conference on Robotics and Automation, 2025We introduce LUMOS, a language-conditioned multi-task imitation learning framework for robotics. LUMOS learns skills by practicing them over many long-horizon rollouts in the latent space of a learned world model and transfers these skills zero-shot to a real robot. By learning on-policy in the latent space of the learned world model, our algorithm mitigates policy-induced distribution shift which most offline imitation learning methods suffer from. LUMOS learns from unstructured play data with fewer than 1% hindsight language annotations but is steerable with language commands at test time. We achieve this coherent long-horizon performance by combining latent planning with both image- and language-based hindsight goal relabeling during training, and by optimizing an intrinsic reward defined in the latent space of the world model over multiple time steps, effectively reducing covariate shift. In experiments on the difficult long-horizon CALVIN benchmark, LUMOS outperforms prior learning-based methods with comparable approaches on chained multi-task evaluations. To the best of our knowledge, we are the first to learn a languageconditioned continuous visuomotor control for a real-world robot within an offline world model.


2024
- Master’s Project
 SAC-N-GMM: Robot Skill Refining and Sequencing for Long-Horizon Manipulation TasksAkshay L Chandra, Iman Nematollahi, and Tim WelscheholdMaster’s Project, Robot Learning Lab [Coursework; Not Peer-Reviewed], Feb 2024
SAC-N-GMM: Robot Skill Refining and Sequencing for Long-Horizon Manipulation TasksAkshay L Chandra, Iman Nematollahi, and Tim WelscheholdMaster’s Project, Robot Learning Lab [Coursework; Not Peer-Reviewed], Feb 2024Despite access to expert data, most long-horizon imitation-learning (IL) agents suffer from distribution shifts, compounding errors, and expert dependency. Several previous works show that refining IL agents in the world with reinforcement learning (RL) alleviates some of these problem by making the agents more robust to noisy perception and stochasticity in dynamics with much helpful real-world exposure. SAC-GMM does this efficiently by first learning a task from demonstrations with a classical robotics technique (e.g., Gaussian Mixture Model) and then refines it with a deep RL (Soft Actor-Critic) agent with sparse task-completion rewards. One could further dampen the side effects of long-horizon IL agents by breaking down complex tasks into short-horizon skills. This simplifies the learning goal into a hierarchy of agents, i.e. high-level planning agent (skill sequencer) and low-level control agent (skill executor). To this end, we propose the Soft Actor-Critic-N -Gaussian Mixture Model (SAC-N-GMM), a novel hybrid RL approach that learns to simultaneously refine and sequence a repertoire of low-level skills to perform numerous combinations of long-horizon tasks. Our approach extends SAC-GMM (1) by learning N lowlevel robot skills with Riemannian Manifold GMMs that learn both robot positions and orientations (2) by learning a single RL agent to refine and sequence multiple manifold-aware GMM skills. Extensive evaluations in the CALVIN simulation environment demonstrate that our approach leverages high-dimensional sensory data, minimal expert demonstrations, minimal physical interactions, and sparse task-completion rewards efficiently to achieve superior long-horizon task performance compared to baselines. Code is available at https://github.com/acl21/sac_n_gmm

2022
- Plant Phenomics
 How Useful Is Image-Based Active Learning for Plant Organ Segmentation?Shivangana Rawat, Akshay L Chandra, Sai Vikas Desai, and 3 more authorsPlant Phenomics, Feb 2022
How Useful Is Image-Based Active Learning for Plant Organ Segmentation?Shivangana Rawat, Akshay L Chandra, Sai Vikas Desai, and 3 more authorsPlant Phenomics, Feb 2022Training deep learning models typically requires a huge amount of labeled data which is expensive to acquire, especially in dense prediction tasks such as semantic segmentation. Moreover, plant phenotyping datasets pose additional challenges of heavy occlusion and varied lighting conditions which makes annotations more time-consuming to obtain. Active learning helps in reducing the annotation cost by selecting samples for labeling which are most informative to the model, thus improving model performance with fewer annotations. Active learning for semantic segmentation has been well studied on datasets such as PASCAL VOC and Cityscapes. However, its effectiveness on plant datasets has not received much importance. To bridge this gap, we empirically study and benchmark the effectiveness of four uncertainty-based active learning strategies on three natural plant organ segmentation datasets. We also study their behaviour in response to variations in training configurations in terms of augmentations used, the scale of training images, active learning batch sizes, and train-validation set splits.

2021
- PMLR/NeurIPS W
 On Initial Pools for Deep Active LearningAkshay L Chandra*, Sai Vikas Desai*, Chaitanya Devaguptapu*, and 1 more authorNeurIPS 2020 Workshop on Pre-registration in Machine Learning, Dec 2021
On Initial Pools for Deep Active LearningAkshay L Chandra*, Sai Vikas Desai*, Chaitanya Devaguptapu*, and 1 more authorNeurIPS 2020 Workshop on Pre-registration in Machine Learning, Dec 2021Active Learning (AL) techniques aim to minimize the training data required to train a model for a given task. Pool-based AL techniques start with a small initial labeled pool and then iteratively pick batches of the most informative samples for labeling. Generally, the initial pool is sampled randomly and labeled to seed the AL iterations. While recent studies have focused on evaluating the robustness of various query functions in AL, little to no attention has been given to the design of the initial labeled pool for deep active learning. Given the recent successes of learning representations in self-supervised/unsupervised ways, we study if an intelligently sampled initial labeled pool can improve deep AL performance. We investigate the effect of intelligently sampled initial labeled pools, including the use of self-supervised and unsupervised strategies, on deep AL methods. The setup, hypotheses, methodology, and implementation details were evaluated by peer review before experiments were conducted. Experimental results could not conclusively prove that intelligently sampled initial pools are better for AL than random initial pools in the long run, although a Variational Autoencoder-based initial pool sampling strategy showed interesting trends that merit deeper investigation.

2020
- Plant Methods
 Active Learning with Point Supervision for Cost-Effective Panicle Detection in Cereal CropsAkshay L Chandra*, Sai Vikas Desai*, Vineeth N Balasubramanian, and 2 more authorsPlant Methods (BioMed Central), Mar 2020
Active Learning with Point Supervision for Cost-Effective Panicle Detection in Cereal CropsAkshay L Chandra*, Sai Vikas Desai*, Vineeth N Balasubramanian, and 2 more authorsPlant Methods (BioMed Central), Mar 2020Panicle density of cereal crops such as wheat and sorghum is one of the main components for plant breeders and agronomists in understanding the yield of their crops. To phenotype the panicle density effectively, researchers agree there is a significant need for computer vision-based object detection techniques. Especially in recent times, research in deep learning-based object detection shows promising results in various agricultural studies. However, training such systems usually requires a lot of bounding-box labeled data. Since crops vary by both environmental and genetic conditions, acquisition of huge amount of labeled image datasets for each crop is expensive and time-consuming. Thus, to catalyze the widespread usage of automatic object detection for crop phenotyping, a cost-effective method to develop such automated systems is essential.
- CVPPP/ECCV Demos
 EasyRFP: An Easy to Use Edge Computing Toolkit for Real-Time Field PhenotypingAkshay L Chandra*, Sai Vikas Desai*, Hirafuji Masayuki, and 3 more authorsExtended Abstract at CVPPP & ECCV Academic Demonstrations, Aug 2020
EasyRFP: An Easy to Use Edge Computing Toolkit for Real-Time Field PhenotypingAkshay L Chandra*, Sai Vikas Desai*, Hirafuji Masayuki, and 3 more authorsExtended Abstract at CVPPP & ECCV Academic Demonstrations, Aug 2020We propose EasyRFP, an edge computing toolkit for real-time field phenotyping. Recent advances in deep learning have catalysed rapid progress in high throughput field phenotyping. Much research has been dedicated towards developing accurate and cost effective deep learning models to capture phenotyping traits such as plant stress, yield and plant growth stages. However, there is a shortage of software tools to promote the usage of such intelligent methods among plant phenotyping practitioners and researchers. To bridge this gap, we developed this, a Flask backend, Angular frontend software toolkit. Broadly speaking, our toolkit can be interfaced with a commercial GPU enabled micro computer (such as NVIDIA Jetson) and a digital camera. Precisely, our toolkit can be used to capture images and extract phenotypic traits in both real-time and in scheduled mode. Currently, we support classification, detection and instance segmentation tasks.


2019
- BMVC
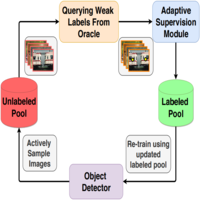 An Adaptive Supervision Framework for Active Learning in Object DetectionSai Vikas Desai*, Akshay L Chandra*, Wei Guo, and 2 more authorsBritish Machine Vision Conference, Aug 2019
An Adaptive Supervision Framework for Active Learning in Object DetectionSai Vikas Desai*, Akshay L Chandra*, Wei Guo, and 2 more authorsBritish Machine Vision Conference, Aug 2019Active learning approaches in computer vision generally involve querying strong labels for data. However, previous works have shown that weak supervision can be effective in training models for vision tasks while greatly reducing annotation costs. Using this knowledge, we propose an adaptive supervision framework for active learning and demonstrate its effectiveness on the task of object detection. Instead of directly querying bounding box annotations (strong labels) for the most informative samples, we first query weak labels and optimize the model. Using a switching condition, the required supervision level can be increased. Our framework requires little to no change in model architecture. Our extensive experiments show that the proposed framework can be used to train good generalizable models with much lesser annotation costs than the state of the art active learning approaches for object detection.
